Introduction
In this vignette, we demonstrate the block bootstrap functionality implemented in nullranges. See the main nullranges vignette for an overview of the idea of bootstrapping, or the diagram below.
nullranges contains an implementation of a block bootstrap for genomic data, as proposed by Bickel et al. (2010), such that features (ranges) are sampled from the genome in blocks. The original block bootstrapping algorithm for genomic data is implemented in a python software called Genome Structure Correlation, GSC.
Our description of the bootRanges methods is described in Mu et al. (2023).
Quick start
Minimal code for running bootRanges() is shown below.
Genome segmentation seg and excluded regions
exclude are optional.
eh <- ExperimentHub()
ah <- AnnotationHub()
# some default resources:
seg <- eh[["EH7307"]] # pre-built genome segmentation for hg38
exclude <- ah[["AH107305"]] # Kundaje excluded regions for hg38, see below
set.seed(5) # set seed for reproducibility
blockLength <- 5e5 # size of blocks to bootstrap
R <- 10 # number of iterations of the bootstrap
# input `ranges` require seqlengths, if missing see `Seqinfo::Seqinfo`
seqlengths(ranges)
# next, we remove non-standard chromosomes ...
library(GenomeInfoDb) # for keepStandardChromosomes()
ranges <- keepStandardChromosomes(ranges, pruning.mode="coarse")
# ... and mitochondrial genome, as these are too short
seqlevels(ranges, pruning.mode="coarse") <- setdiff(seqlevels(ranges), "MT")
# generate bootstraps
boots <- bootRanges(ranges, blockLength=blockLength, R=R,
seg=seg, exclude=exclude)
# `boots` can then be used with plyranges commands, e.g. join_overlap_*The boots object will contain a column,
iter which marks the different bootstrap samples that were
generated. This allows for tidy analysis with plyranges,
e.g. counting the number of overlapping ranges, per bootstrap iteration.
For more examples of combining bootRanges with
plyranges operations, see the tidy ranges
tutorial.
Method overview
Several algorithms are implemented in bootRanges(),
including a segmented and unsegmented version, where in the former,
blocks are sampled with respect to a particular genome segmentation.
Overall, we recommend the segmented block bootstrap given the
heterogeneity of structure across the entire genome. If the purpose is
block bootstrapping ranges within a smaller set of sequences, such as
motifs within transcript sequence, then the unsegmented algorithm would
be sufficient.
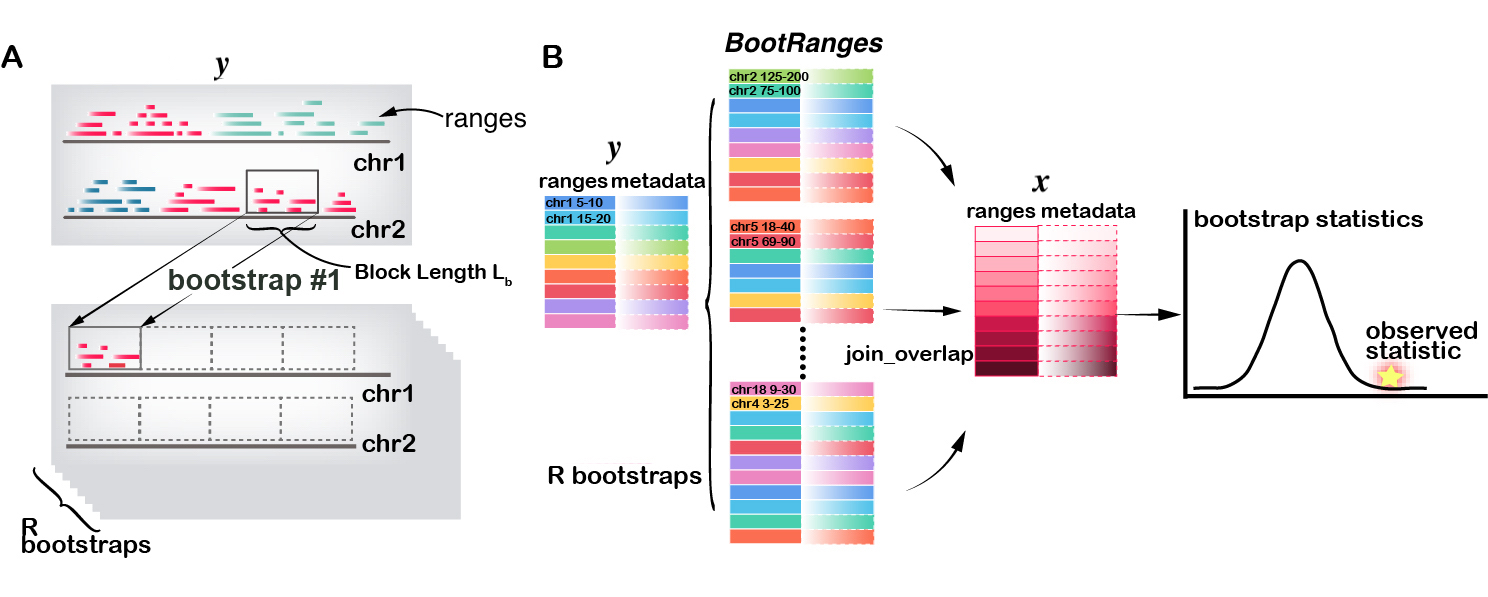
In a segmented block bootstrap, the blocks are sampled and placed within regions of a genome segmentation. That is, for a genome segmented into states , only blocks from state s will be used to sample the ranges of state s in each bootstrap sample. The process can be visualized in diagram panel (A) below, where a block with length is randomly sampled with replacement from state “red” and the features (ranges) that overlap this block are then copied to the first tile (which is in the “red” state). The sampling is allowed across chromosome (as shown here), as long as the two blocks are in the same state.
Note that nullranges provides both functions for generating a genome segmentation from e.g. gene density, described below, as well as a default segmentation for hg38 that can be used directly.
An example workflow of bootRanges() used in combination
with plyranges (Lee et al. 2019)
is diagrammed in panel (B) below, and can be summarized as:
- Compute statistics of interest between GRanges of feature and GRanges of feature to assess association in the original data. This could be an enrichment (amount of overlap) or other possible statistics making use of covariates associated with each range
- Generate bootstrap samples of
:
bootRanges()with optional argumentsseg(segmentation) andexclude(excluded regions as compiled by Ogata et al. (2023)) to create a BootRanges object () - Compute the bootstrap distribution of test statistics between GRanges of feature and using plyranges (compute overlaps of all features in with all features in , grouping by the bootstrap sample)
- Conpute a bootstrap p-value or test to test the null hypothesis that there is no association between and (e.g. that the bootstrap data often has as high an enrichment as the observed data)
In this vignette, we give an example of segmenting the hg38 genome by
Ensembl gene density, performing bootstrap sampling of peaks ranges, and
evaluating overlaps for observed peaks and bootstrap peaks. We also
provide other examples of statistics that can be computed with the
bootRanges framework, including a single cell multi-omics
example and a special case of bootstrapping features in one region of
the genome.
Proportional blocks: A finally consideration is
whether the blocks used to generate the bootstrap samples should scale
proportionally to the segment state length, with the default setting of
proportionLength=TRUE. When blocks scale proportionally,
blockLength provides the maximal length of a block, while
the actual block length used for a segmentation state is proportional to
the fraction of genomic basepairs covered by that state. It is
theoretically motivated to have the blocks scale with the overall extent
of the segment state. However, in practice, if the genome segmentation
states are very heterogeneous in size (e.g. orders of magnitude
differences), then the blocks constructed via the proportional length
method for the smaller segmentation states can be too short to
effectively capture inter-range distances. We therefore recommend
proportional length blocks unless some segmentation states have a much
smaller extent than others, in which case fixed length blocks can be
used. This option is visualized on toy data at the end of this
vignette.
Steps before bootstrapping
Import excluded regions
To avoid placing bootstrap features into regions of the genome that don’t typically have features, we import excluded regions including ENCODE-produced excludable regions(Amemiya et al. 2019), telomeres from UCSC, centromeres. These, and other excludable sets, are assembled in the excluderanges package (Ogata et al. 2023).
suppressPackageStartupMessages(library(AnnotationHub))
ah <- AnnotationHub()
# hg38.Kundaje.GRCh38_unified_Excludable
exclude_1 <- ah[["AH107305"]]
# hg38.UCSC.centromere
exclude_2 <- ah[["AH107354"]]
# hg38.UCSC.telomere
exclude_3 <- ah[["AH107355"]]
# hg38.UCSC.short_arm
exclude_4 <- ah[["AH107356"]]
# combine them
suppressWarnings({
exclude <- trim(c(exclude_1, exclude_2, exclude_3, exclude_4))
})
exclude <- sort(GenomicRanges::reduce(exclude))Genome segmentation
For most genomic datasets we examine, the density of ranges of interest (e.g. ChIP- or ATAC-seq peaks) is often correlated to other large-scale patterns of other genomic features, such as density of genes. Bickel et al. (2010) therefore proposed the idea of bootstrapping with respect to a segmented genome given known, large-scale genomic structures such as isochores (“larger than 300kb”).
A genomic segmentation can be considered if it defines large (e.g. on the order of ∼1 Mb), relatively homogeneous segments with respect to feature density, and the variance of the distribution of the test statistics become stable as block length increases (see Mu et al. (2023) Fig 2A).
There are two options for choosing a segmentation, either:
- Use an exiting segmentation (e.g. ChromHMM, etc.) downloaded from AnnotationHub or external to Bioconductor (BED files imported with rtracklayer)
- Perform a de novo segmentation of the genome using feature density, e.g. gene density
Pre-built segmentations
Given that these genome segmentation evaluations take time and involve consideration of multiple criteria, we have provided our recommended segmentation for hg38. nullranges has generated pre-built segmentations for easy use, which were generated using code outlined below in the Segmentation by gene density section.
Pre-built segmentations using either CBS or HMM methods with considering excludable regions can be downloaded directly from ExperimentHub. We find that the segmentation and block length (500kb) shown in the case study below could be used for most analyses of hg38.
suppressPackageStartupMessages(library(ExperimentHub))
eh <- ExperimentHub()
seg_cbs <- eh[["EH7307"]] # prefer CBS for hg38
seg_hmm <- eh[["EH7308"]]
seg <- seg_cbsSegmentation by gene density
This section describes how we generated the pre-built segmentations, such that users with a different genome can generate a segmentation for their own purposes. First we obtain the Ensembl genes (Howe et al. 2020) for segmenting by gene density. We obtain these using the ensembldb package (Rainer et al. 2019).
suppressPackageStartupMessages(library(ensembldb))
suppressPackageStartupMessages(library(EnsDb.Hsapiens.v86))
edb <- EnsDb.Hsapiens.v86
filt <- AnnotationFilterList(GeneIdFilter("ENSG", "startsWith"))
g <- genes(edb, filter = filt)We perform some processing to align the sequences (chromosomes) of
g with our excluded regions and our features of interest
(DNase hypersensitive sites, or DHS, defined below).
library(GenomeInfoDb) # for keepStandardChromosomes()
g <- keepStandardChromosomes(g, pruning.mode = "coarse")
# MT is too small for bootstrapping, so must be removed
seqlevels(g, pruning.mode="coarse") <- setdiff(seqlevels(g), "MT")
# normally we would assign a new style, but for recent host issues
# that produced vignette build problems, we use `paste0`
## seqlevelsStyle(g) <- "UCSC"
seqlevels(g) <- paste0("chr", seqlevels(g))
genome(g) <- "hg38"
g <- sortSeqlevels(g)
g <- sort(g)
table(seqnames(g))##
## chr1 chr2 chr3 chr4 chr5 chr6 chr7 chr8 chr9 chr10 chr11 chr12 chr13
## 5194 3971 3010 2505 2868 2863 2867 2353 2242 2204 3235 2940 1304
## chr14 chr15 chr16 chr17 chr18 chr19 chr20 chr21 chr22 chrX chrY
## 2224 2152 2511 2995 1170 2926 1386 835 1318 2359 523CBS segmentation
We first demonstrate the use of a CBS segmentation as implemented in DNAcopy (Olshen et al. 2004).
We load the nullranges and plyranges packages, and patchwork in order to produce grids of plots.
library(nullranges)
suppressPackageStartupMessages(library(plyranges))
library(patchwork)We subset the excluded ranges to those which are 500 bp or larger.
The motivation for this step is to avoid segmenting the genome into many
small pieces due to an abundance of short excluded regions. Note that we
re-save the excluded ranges to exclude.
set.seed(5)
exclude <- exclude %>%
filter(width(exclude) >= 500)
L_s <- 1e6
seg_cbs <- segmentDensity(g, n = 3, L_s = L_s,
exclude = exclude, type = "cbs")## Analyzing: Sample.1
plots <- lapply(c("ranges","barplot","boxplot"), function(t) {
plotSegment(seg_cbs, exclude, type = t)
})
plots[[1]]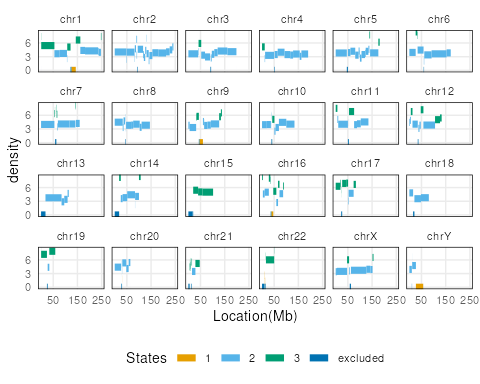
plots[[2]] + plots[[3]]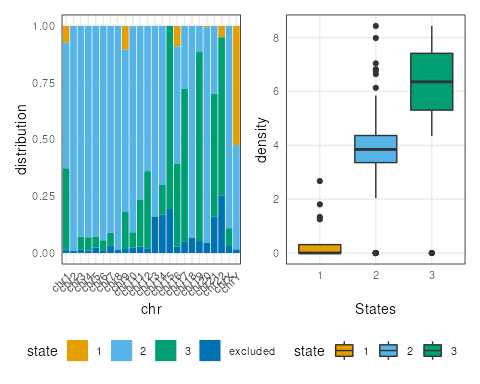
Note here, the default ranges plot shows the whole genome.
Some of the state transitions within small regions cannot be visualized.
One can look into specific regions to observe segmentation states, by
specifying the region argument.
region <- GRanges("chr16", IRanges(3e7,4e7))
plotSegment(seg_cbs, exclude, type="ranges", region=region)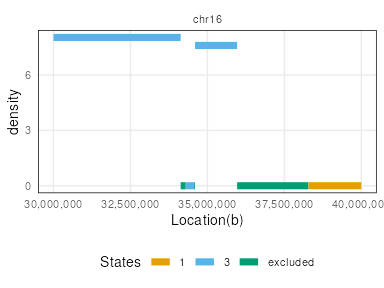
Alternatively: HMM segmentation
Here we use an alternative segmentation implemented in the
RcppHMM CRAN package, using the initGHMM,
learnEM, and viterbi functions.
seg_hmm <- segmentDensity(g, n = 3, L_s = L_s,
exclude = exclude, type = "hmm")## Finished at Iteration: 127 with Error: 9.70053e-06
plots <- lapply(c("ranges","barplot","boxplot"), function(t) {
plotSegment(seg_hmm, exclude, type = t)
})
plots[[1]]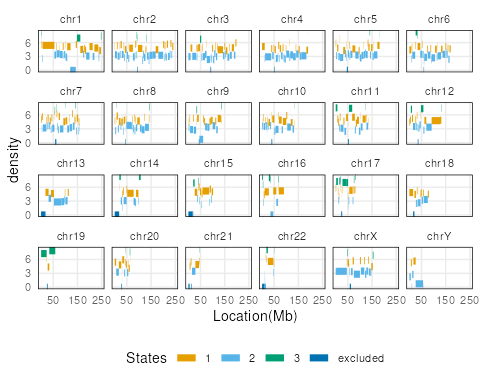
plots[[2]] + plots[[3]]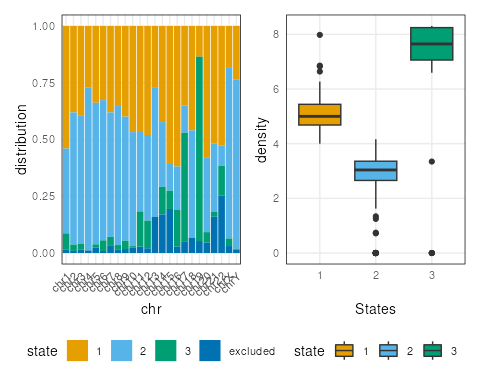
Bootstrapping ranges
We use a set of DNase hypersensitivity sites (DHS) from the ENCODE project (ENCODE 2012) in A549 cell line (ENCSR614GWM). Here, for speed, we work with a pre-processed data object from ExperimentHub, created using the following steps:
- Download ENCODE DNase hypersensitive peaks in A549 from AnnotationHub
- Subset to standard chromosomes and remove mitochondrial DNA
- Use a chain file from UCSC to lift ranges from hg19 to hg38
- Sort the DHS features to be bootstrapped
These steps are included in nullrangesData in the
inst/scripts/make-dhs-data.R script.
For speed of the vignette, we restrict to a smaller number of DHS,
filtering by the signal value. We also remove unrelated metadata columns
that we don’t need for the bootstrap analysis. Because we are interested
in signal value for DHS peaks later, we only keep this column. Consider,
when creating bootstrapped data, that you will be creating an object
many times larger than your original data (i.e. multipled by
R the number of bootstrap iterations), so
filtering down to key ranges and
selecting only the relevant metadata can help make the
analysis much more efficient.
suppressPackageStartupMessages(library(nullrangesData))
dhs <- DHSA549Hg38()
dhs <- dhs %>% filter(signalValue > 100) %>%
mutate(id = seq_along(.)) %>%
select(id, signalValue)
length(dhs)## [1] 6214##
## chr1 chr2 chr3 chr4 chr5 chr6 chr7 chr8 chr9 chr10 chr11 chr12 chr13
## 1436 252 108 30 148 51 184 146 155 443 436 526 20
## chr14 chr15 chr16 chr17 chr18 chr19 chr20 chr21 chr22 chrX chrY
## 197 265 214 715 20 649 142 31 19 17 10Now we apply a segmented block bootstrap with blocks of size 500kb, to the peaks. Here we show generation of 50 iterations of a block bootstrap followed by a typical overlap analysis using plyranges (Lee et al. 2019).
Note that we have already removed non-standard chromosomes and
mitochondrial chromosome, as these are typically shorter than our
desired blockLength (see e.g. code in Quick Start
above).
set.seed(5) # for reproducibility
R <- 50
blockLength <- 5e5
boots <- bootRanges(dhs, blockLength, R = R, seg = seg, exclude=exclude)
boots## BootRanges object with 310434 ranges and 3 metadata columns:
## seqnames ranges strand | id signalValue iter
## <Rle> <IRanges> <Rle> | <integer> <numeric> <Rle>
## [1] chr1 242791-242940 * | 347 120 1
## [2] chr1 256031-256180 * | 348 194 1
## [3] chr1 391535-391684 * | 5301 109 1
## [4] chr1 421046-421195 * | 5302 106 1
## [5] chr1 438186-438335 * | 5303 232 1
## ... ... ... ... . ... ... ...
## [310430] chrY 27090908-27091057 * | 2133 105 50
## [310431] chrY 27194968-27195117 * | 2134 128 50
## [310432] chrY 27224188-27224337 * | 2135 153 50
## [310433] chrY 27234153-27234302 * | 2136 125 50
## [310434] chrY 27789879-27790028 * | 2116 118 50
## -------
## seqinfo: 24 sequences from hg38 genomeWhat is returned here? The bootRanges function returns a
BootRanges object, which is a simple sub-class of
GRanges. The iteration (iter) and (optionally) the
block length (blockLength) are recorded as metadata
columns, accessible via mcols. We return the bootstrapped
ranges as GRanges rather than GRangesList, as the
former is more compatible with downstream overlap joins with
plyranges, where the iteration column can be used with
group_by to provide per bootstrap summary statistics, as
shown below.
Note that we use the exclude object from the previous
step, which does not contain small ranges. If one wanted to also avoid
generation of bootstrapped features that overlap small excluded ranges,
then omit this filtering step (use the original, complete
exclude feature set).
Assessing properties of bootstrap samples
We can examine properties of permuted y over iterations, and compare to the original y. To do so, we first add the original features as iter=0. Then compute summaries:
suppressPackageStartupMessages(library(tidyr))
combined <- dhs %>%
mutate(iter=0) %>%
bind_ranges(boots) %>%
select(iter)
stats <- combined %>%
group_by(iter) %>%
summarize(n = n()) %>%
as_tibble()
head(stats)## # A tibble: 6 × 2
## iter n
## <fct> <int>
## 1 0 6214
## 2 1 6144
## 3 2 6265
## 4 3 6233
## 5 4 6291
## 6 5 6357Bootstrapping and plyranges
We will now show how to combine bootstrapping with plyranges
to perform statistical enrichment analysis. The general idea will be to
combine the long vector of bootstrapped ranges, indexed by
iter, with another set of ranges to compute enrichment. We
will explore this idea across a number of case studies below. In
pseudocode, the general outline will be:
# pseudocode for the general paradigm:
boots <- bootRanges(y) # make bootstrapped y
x %>% join_overlap_inner(boots) %>% # overlaps of x with bootstrapped y
group_by(x_id, iter) %>% # collate by x ID and the bootstrap iteration
summarize(some_statistic = ...) %>% # compute some summary on metadata
as_tibble() %>% # pass to tibble
complete(
x_id, iter, # for any missing combinations of x ID and iter...
fill=list(some_statistic = 0) # ...fill in missing values
)Counting the total number of overlaps
Suppose we have a set of features x and we are
interested in evaluating the enrichment of this set with the DHS. We can
calculate for example the sum observed number of overlaps for features
in x with DHS in whole genome (or something more
complicated, e.g. the maximum log fold change or signal value for DHS
peaks within a maxgap window of x).
x <- x %>% mutate(n_overlaps = count_overlaps(., dhs))
sum( x$n_overlaps )## [1] 64We can repeat this with the bootstrapped features using a
group_by command, a summarize, followed by a
second group_by and summarize. If it is your
first time working with plyranges, it may help you to step
through these commands one by one, breaking the pipe at intermediate
points, to understand what the intermediate output is, and how it
combines to provide the final statistics.
Note that we need to use tidyr::complete in order to
fill in combinations of x and iter where the
overlap was 0.
boot_stats <- x %>% join_overlap_inner(boots) %>%
group_by(x_id, iter) %>%
summarize(n_overlaps = n()) %>%
as_tibble() %>%
complete(x_id, iter, fill=list(n_overlaps = 0)) %>%
group_by(iter) %>%
summarize(sumOverlaps = sum(n_overlaps))The above code, first grouping by x_id and
iter, then subsequently by iter is general and
allows for more complex analysis than just mean overlap (e.g. how many
times an x range has 1 or more overlap, what is the mean or
max signal value for peaks overlapping ranges in x,
etc.).
If one is interested in assessing feature-wise statistics
instead of genome-wise statistics, eg.,the mean observed number
of overlaps per feature or mean base pair overlap in x, one
can also group by both (block,iter). 10,000
total blocks may therefore be sufficient to derive a bootstrap
distribution, avoiding the need to generate many bootstrap genomes of
data.
Finally we can plot a histogram. In this case, as the x
features were arbitrary, our observed value falls within the
distribution of sum number of overlap bootstrapped peaks with
.
suppressPackageStartupMessages(library(ggplot2))
ggplot(boot_stats, aes(sumOverlaps)) +
geom_histogram(binwidth=5)+
geom_vline(xintercept = sum(x$n_overlaps), linetype = "dashed")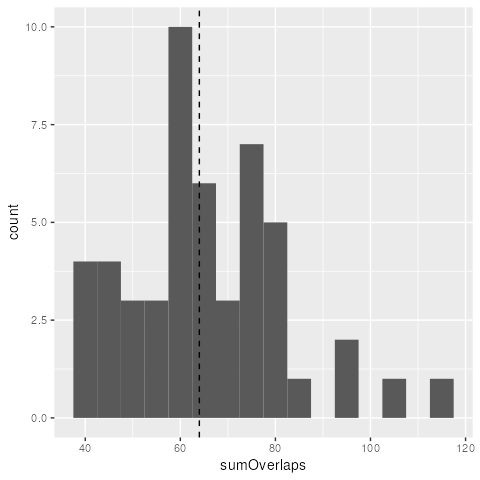
Computing the sum of signal value for nearby peaks
x_obs <- x %>% join_overlap_inner(dhs,maxgap=1e3)
sum(x_obs$signalValue )## [1] 9503
boot_stats <- x %>% join_overlap_inner(boots,maxgap=1e3) %>%
group_by(x_id, iter) %>%
summarize(Signal = sum(signalValue)) %>%
as_tibble() %>%
complete(x_id, iter, fill=list(Signal = 0)) %>%
group_by(iter) %>%
summarize(sumSignal = sum(Signal))Still in this case, our observed value falls within the distribution of bootstrapped statistics.
ggplot(boot_stats, aes(sumSignal)) +
geom_histogram()+
geom_vline(xintercept = sum(x_obs$signalValue), linetype = "dashed")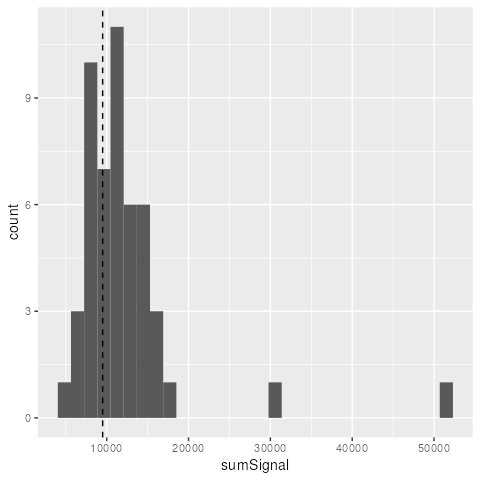
Block bootstrapping one region
Generally, it makes sense to block bootstrap the entire genome at once. This is motivated by the “tidy analysis” paradigm where loops are avoided by stacking data into a longer format. This makes computation more efficient in our case (as a single overlap call can be made with all regions of interest at once, across multiple bootstrap iterations), and it also can simplify code and avoid repetition.
However, in some cases, there is a single region of interest, and it is desired to generate bootstrap data within this one region. For this, we have a convenience function that enables bootstrap computation.
Suppose we have data in the following region of chromosome 1:
suppressPackageStartupMessages(library(nullrangesData))
dhs <- DHSA549Hg38()
region <- GRanges("chr1", IRanges(10e6 + 1, width=1e6))
x <- GRanges("chr1", IRanges(10e6 + 0:9 * 1e5 + 1, width=1e4))
y <- dhs %>% filter_by_overlaps(region) %>% select(NULL)
x %>% mutate(num_overlaps = count_overlaps(., y))## GRanges object with 10 ranges and 1 metadata column:
## seqnames ranges strand | num_overlaps
## <Rle> <IRanges> <Rle> | <integer>
## [1] chr1 10000001-10010000 * | 0
## [2] chr1 10100001-10110000 * | 2
## [3] chr1 10200001-10210000 * | 1
## [4] chr1 10300001-10310000 * | 0
## [5] chr1 10400001-10410000 * | 5
## [6] chr1 10500001-10510000 * | 2
## [7] chr1 10600001-10610000 * | 0
## [8] chr1 10700001-10710000 * | 0
## [9] chr1 10800001-10810000 * | 1
## [10] chr1 10900001-10910000 * | 1
## -------
## seqinfo: 1 sequence from an unspecified genome; no seqlengthsWe can easily bootstrap data just in this region using the following code:
seg <- oneRegionSegment(region, seqlength=248956422)
seqlevels(y) <- "chr1"
set.seed(1)
boot <- bootRanges(y, blockLength=1e5, R=1, seg=seg,
proportionLength=FALSE)
boot## BootRanges object with 83 ranges and 1 metadata column:
## seqnames ranges strand | iter
## <Rle> <IRanges> <Rle> | <Rle>
## [1] chr1 10001821-10001970 * | 1
## [2] chr1 10002381-10002530 * | 1
## [3] chr1 10003041-10003190 * | 1
## [4] chr1 10003536-10003685 * | 1
## [5] chr1 10004001-10004150 * | 1
## ... ... ... ... . ...
## [79] chr1 10918882-10919031 * | 1
## [80] chr1 10953082-10953231 * | 1
## [81] chr1 10961702-10961851 * | 1
## [82] chr1 10993742-10993891 * | 1
## [83] chr1 10995862-10996011 * | 1
## -------
## seqinfo: 1 sequence from hg38 genome
x %>% mutate(num_overlaps = count_overlaps(., boot))## GRanges object with 10 ranges and 1 metadata column:
## seqnames ranges strand | num_overlaps
## <Rle> <IRanges> <Rle> | <integer>
## [1] chr1 10000001-10010000 * | 5
## [2] chr1 10100001-10110000 * | 0
## [3] chr1 10200001-10210000 * | 1
## [4] chr1 10300001-10310000 * | 5
## [5] chr1 10400001-10410000 * | 1
## [6] chr1 10500001-10510000 * | 0
## [7] chr1 10600001-10610000 * | 5
## [8] chr1 10700001-10710000 * | 0
## [9] chr1 10800001-10810000 * | 5
## [10] chr1 10900001-10910000 * | 0
## -------
## seqinfo: 1 sequence from an unspecified genome; no seqlengthsHere it is important to use proportionLength=FALSE so
that the blocks will be of the size specified and not smaller (they
would otherwise be scaled down proportional to the fraction of
region compared to the chromosome).
Visualizing bootstrap types
Below we present a toy example for visualizing the segmented block bootstrap. First, we define a helper function for plotting GRanges using plotgardener (Kramer et al. 2022). A key aspect here is that we color the original and bootstrapped ranges by the genomic state (the state of the segmentation that the original ranges fall in).
suppressPackageStartupMessages(library(plotgardener))
my_palette <- function(n) {
head(c("red","green3","red3","dodgerblue",
"blue2","green4","darkred"), n)
}
plotGRanges <- function(gr) {
pageCreate(width = 5, height = 5, xgrid = 0,
ygrid = 0, showGuides = TRUE)
for (i in seq_along(seqlevels(gr))) {
chrom <- seqlevels(gr)[i]
chromend <- seqlengths(gr)[[chrom]]
suppressMessages({
p <- pgParams(chromstart = 0, chromend = chromend,
x = 0.5, width = 4*chromend/500, height = 2,
at = seq(0, chromend, 50),
fill = colorby("state_col", palette=my_palette))
prngs <- plotRanges(data = gr, params = p,
chrom = chrom,
y = 2 * i,
just = c("left", "bottom"))
annoGenomeLabel(plot = prngs, params = p, y = 0.1 + 2 * i)
})
}
}Create a toy genome segmentation:
library(GenomicRanges)
seq_nms <- rep(c("chr1","chr2"), c(4,3))
seg <- GRanges(
seqnames = seq_nms,
IRanges(start = c(1, 101, 201, 401, 1, 201, 301),
width = c(100, 100, 200, 100, 200, 100, 100)),
seqlengths=c(chr1=500,chr2=400),
state = c(1,2,1,3,3,2,1),
state_col = factor(1:7)
)We can visualize with our helper function:
plotGRanges(seg)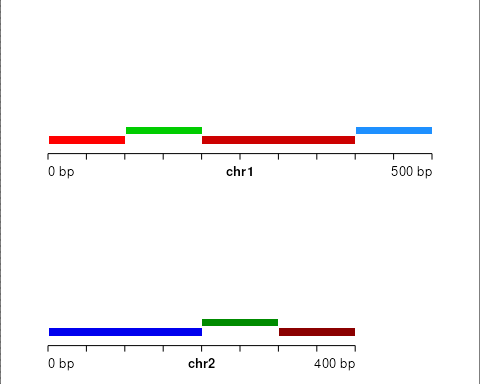
Now create small ranges distributed uniformly across the toy genome:
set.seed(1)
n <- 200
gr <- GRanges(
seqnames=sort(sample(c("chr1","chr2"), n, TRUE)),
IRanges(start=round(runif(n, 1, 500-10+1)), width=10)
)
suppressWarnings({
seqlengths(gr) <- seqlengths(seg)
})
gr <- gr[!(seqnames(gr) == "chr2" & end(gr) > 400)]
gr <- sort(gr)
idx <- findOverlaps(gr, seg, type="within", select="first")
gr <- gr[!is.na(idx)]
idx <- idx[!is.na(idx)]
gr$state <- seg$state[idx]
gr$state_col <- factor(seg$state_col[idx])
plotGRanges(gr)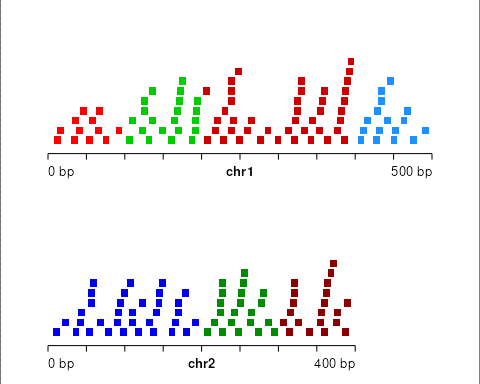
Scaling vs. not scaling by segment length
We can visualize block bootstrapped ranges when the blocks do not scale to segment state length:
set.seed(1)
gr_prime <- bootRanges(gr, blockLength = 25, seg = seg,
proportionLength = FALSE)
plotGRanges(gr_prime)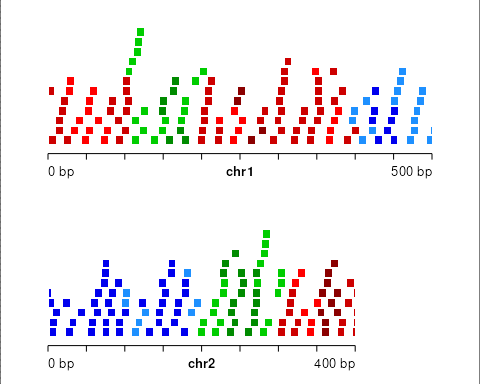
This time the blocks scale to the segment state length. Note that in
this case blockLength is the maximal block length
possible, but the actual block lengths per segment will be smaller
(proportional to the fraction of basepairs covered by that state in the
genome segmentation).
set.seed(1)
gr_prime <- bootRanges(gr, blockLength = 50, seg = seg,
proportionLength = TRUE)
plotGRanges(gr_prime)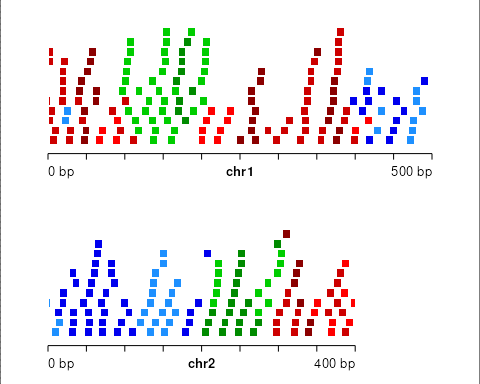
Note that some ranges from adjacent states are allowed to be placed within different states in the bootstrap sample. This is because, during the random sampling of blocks of original data, a block is allowed to extend beyond the segmentation region of the state being sampled, and features from adjacent states are not excluded from the sampled block.
Session information
## R version 4.5.2 (2025-10-31)
## Platform: x86_64-pc-linux-gnu
## Running under: Ubuntu 24.04.3 LTS
##
## Matrix products: default
## BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
## LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
##
## locale:
## [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
## [3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
## [5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
## [7] LC_PAPER=en_US.UTF-8 LC_NAME=C
## [9] LC_ADDRESS=C LC_TELEPHONE=C
## [11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
##
## time zone: UTC
## tzcode source: system (glibc)
##
## attached base packages:
## [1] stats4 stats graphics grDevices utils datasets methods
## [8] base
##
## other attached packages:
## [1] plotgardener_1.16.0 ggplot2_4.0.1
## [3] tidyr_1.3.1 patchwork_1.3.2
## [5] plyranges_1.30.1 dplyr_1.1.4
## [7] nullranges_1.17.3 GenomeInfoDb_1.46.0
## [9] EnsDb.Hsapiens.v86_2.99.0 ensembldb_2.34.0
## [11] AnnotationFilter_1.34.0 GenomicFeatures_1.62.0
## [13] AnnotationDbi_1.72.0 nullrangesData_1.16.0
## [15] InteractionSet_1.38.0 SummarizedExperiment_1.40.0
## [17] Biobase_2.70.0 MatrixGenerics_1.22.0
## [19] matrixStats_1.5.0 ExperimentHub_3.0.0
## [21] GenomicRanges_1.62.0 Seqinfo_1.0.0
## [23] IRanges_2.44.0 S4Vectors_0.48.0
## [25] AnnotationHub_4.0.0 BiocFileCache_3.0.0
## [27] dbplyr_2.5.1 BiocGenerics_0.56.0
## [29] generics_0.1.4
##
## loaded via a namespace (and not attached):
## [1] DBI_1.2.3 bitops_1.0-9 httr2_1.2.1
## [4] rlang_1.1.6 magrittr_2.0.4 ggridges_0.5.7
## [7] compiler_4.5.2 RSQLite_2.4.4 png_0.1-8
## [10] systemfonts_1.3.1 vctrs_0.6.5 ProtGenerics_1.42.0
## [13] pkgconfig_2.0.3 crayon_1.5.3 fastmap_1.2.0
## [16] XVector_0.50.0 labeling_0.4.3 utf8_1.2.6
## [19] Rsamtools_2.26.0 rmarkdown_2.30 UCSC.utils_1.6.0
## [22] strawr_0.0.92 ragg_1.5.0 purrr_1.2.0
## [25] bit_4.6.0 RcppHMM_1.2.2.1 xfun_0.54
## [28] cachem_1.1.0 cigarillo_1.0.0 jsonlite_2.0.0
## [31] blob_1.2.4 rhdf5filters_1.22.0 DelayedArray_0.36.0
## [34] Rhdf5lib_1.32.0 BiocParallel_1.44.0 parallel_4.5.2
## [37] R6_2.6.1 bslib_0.9.0 RColorBrewer_1.1-3
## [40] rtracklayer_1.70.0 DNAcopy_1.84.0 jquerylib_0.1.4
## [43] Rcpp_1.1.0 knitr_1.50 Matrix_1.7-4
## [46] tidyselect_1.2.1 abind_1.4-8 yaml_2.3.10
## [49] codetools_0.2-20 curl_7.0.0 lattice_0.22-7
## [52] tibble_3.3.0 withr_3.0.2 KEGGREST_1.50.0
## [55] S7_0.2.1 evaluate_1.0.5 gridGraphics_0.5-1
## [58] desc_1.4.3 Biostrings_2.78.0 pillar_1.11.1
## [61] BiocManager_1.30.27 filelock_1.0.3 RCurl_1.98-1.17
## [64] BiocVersion_3.22.0 scales_1.4.0 glue_1.8.0
## [67] lazyeval_0.2.2 tools_4.5.2 BiocIO_1.20.0
## [70] data.table_1.17.8 GenomicAlignments_1.46.0 fs_1.6.6
## [73] XML_3.99-0.20 rhdf5_2.54.0 grid_4.5.2
## [76] restfulr_0.0.16 cli_3.6.5 rappdirs_0.3.3
## [79] textshaping_1.0.4 S4Arrays_1.10.0 gtable_0.3.6
## [82] yulab.utils_0.2.1 sass_0.4.10 digest_0.6.39
## [85] ggplotify_0.1.3 SparseArray_1.10.1 rjson_0.2.23
## [88] htmlwidgets_1.6.4 farver_2.1.2 memoise_2.0.1
## [91] htmltools_0.5.8.1 pkgdown_2.2.0 lifecycle_1.0.4
## [94] httr_1.4.7 bit64_4.6.0-1